

Hablemos más profundamente sobre los índices,
¿Qué son los índices?
Los índices son una forma muy eficiente de buscar los datos por un valor específico y nos evita tener que recorrer toda la colección en busca de un dato específico.
Los índices en las bases de datos tradicionales se basan en Binary Tree Sort, y Mongo también.
Veamos de una forma muy resumida como funcionaría este tipo de algoritmo.
Binary Tree Sort
Para que nos hagamos una idea, es un tipo específico de ordenación que tiene esta pinta
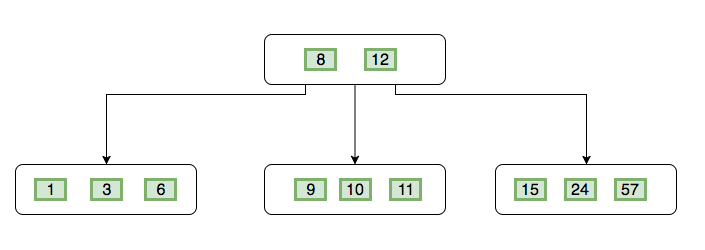
Supongamos entonces que buscamos el número 10, en la búsqueda lo que hace es comprobar los números en la posición en la que está y sigue estos pasos:
- ¿El número que busco es menor que 8? No.
- ¿Está entre 8 - 12? Sí. Paso la búsqueda por la rama central.
Básicamente sigue este orden:
- Si es menor que el número más a la izquierda pasamos la búsqueda por la rama que esté más a la izquierda.
- Si está entre números lo mando por la rama que comprenda esos números.
- Si el número es mayor que el número que esta más a la derecha envío la búsqueda por la rama que está más a la derecha.
Y así con tantos niveles como tenga el árbol. Aunque en conjunto pueda ser algo más complicado que esto, pero esta es la teoría fundamental de este algoritmo de ordenación/búsqueda. Por dar un dato extra la fórmula de lo que tarda en la búsqueda sería:
O(log(n))
Creo que no tengo la capacidad para explicar bien la fórmula, tenéis un montón de información al respecto por internet. Info
Y, ¿que hace la indexación con este algoritmo?...a parte de ordenar los datos de esa manera, intenta que un bloque de números entre en un sector del disco, lo que hace que en una sola pasada sea capaz de leer todos los números de un bloque y así en conjunto se consigue que la búsqueda de elementos sea realmente rápida.
Y después de comentar sobre BTS (Binary Tree Search) continuemos hablando de los índices.
Tipos de índices
Ahora viene el cambio de concepto, ya hemos visto en post anteriores como se hacian los índices, digamos, simples
db.collectionName.createIndex({nombreDelCampo: Ascendente/descendente})
db.heros.createIndex({money:1})
Estos son los índices más habituales y son los que usan BTS realmente, pero tenemos otros 2 tipos de índices que no usan este mecanismo de ordenación:
- Full text Index: Indices de texto libre. Nos permite buscar el texto que hay en los documentos, es una búsqueda tipo Google. Al generar este tipo de índice crea una base de datos grande con todos los documentos de tipo texto (según los criterios que indiquemos) y a la hora de buscar nos muestras los elementos por relevancia (cuanto más aparezca la palabra que buscamos en el documento, más relevante se vuelve)
- Geospatial Index: Indices de búsqueda geoespacial, que nos permiten manejar datos geográficos, latitudes y longitudes pero no solo puntos si no, nos permiten hacer búsquedas por zonas (en plan datos a mi alrededor o a X Km o si tengo por ejemplo una línea de las de Google maps ruta/origen/destino podríamos buscar lo que está cerca de la línea). Esto se vuelve muy útil para aplicaciones móviles por ejemplo.
Full text Index
Primero veamos como crear este tipo de índice:
db.nameCollection.createIndex({"fieldName": "text"})
db.heros.createIndex({ name: "text"})
Si os fijáis un poco, se crean de la misma forma que habitualmente, solo que en lugar de indicarle la dirección del índice(ascendente/descendente con +/-1) lo que hacemos es indicarle que es de tipo text.
Esto nos crea una especie de índice invertido, en el que en lugar de indexar al estilo "esta palabra está en todos estos documentos", lo que hace es darle la vuelta, es decir, este documento tiene estas palabras.
Si hacemos la prueba con el campo name de nuestra colección (sé que no tiene sentido es un campo muy pequeño pero para hacer las pruebas nos vale) y mostramos los índices:
db.heros.getIndexes()
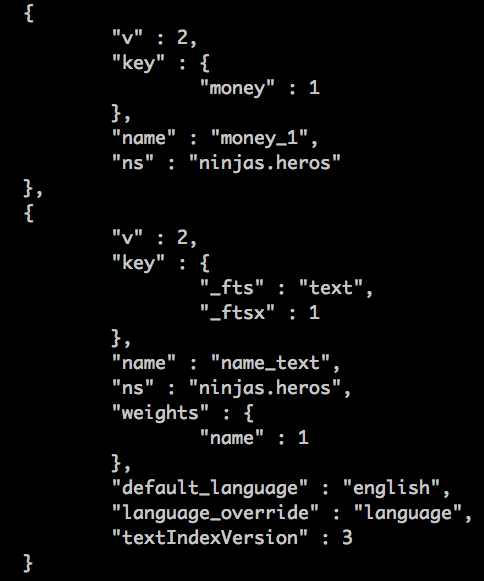
Vemos como cambia bastante la configuración de uno a otro (el de arriba sería el normal que hicimos con el campo money y el de abajo sería el nuevo).
Para hacer la prueba vamos a cambiarle el nombre a Batman por un párrafo de texto como este:
"Hero can be anyone. Even a man knowing something as simple and reassuring as putting a coat around a young boy shoulders to let him know the world hadn't ended."
Para hacerlo, ya sabéis con:
db.heros.update({_id:ObjectId("59e1ff63c5662c1d57baf715")},{$set: {name:"Hero can be anyone. Even a man knowing something as simple and reassuring as putting a coat around a young boy shoulders to let him know the world hadn't ended."}})
Perfecto, y ahora para buscar en este formato:
db.collectionName.find({$text: {$search: ""}})
Dentro del habitual find para filtrar tenemos:
- $text: Con esto le indicamos que haga una búsqueda de tipo texto.
- $search: Con search lo que hacemos es indicarle que busque por algo.
Hagamos alguna búsqueda para ver que pasa:
db.heros.find({$text: {$search: "coat"}}).pretty()
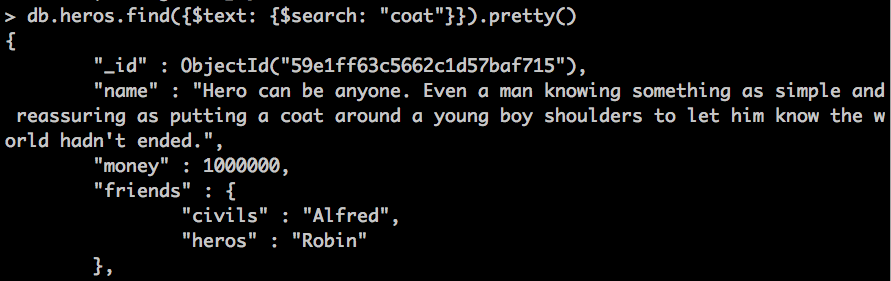
Como véis lo encuentra sin problemas. Las búsquedas de este tipo en mongo parecen ser bastante inteligentes, ignoran las típicas palabras comodines como pueden ser en ingles un "a" o "the" y se centra en el resto, también busca por raiz de palabra, es decir, por palabras que contengan la palabra que estamos buscando (OJO tienen que ser palabras en sí y no mezclas de comodines como some..), por ejemplo:
db.heros.find({$text: {$search: "put"}}).pretty()
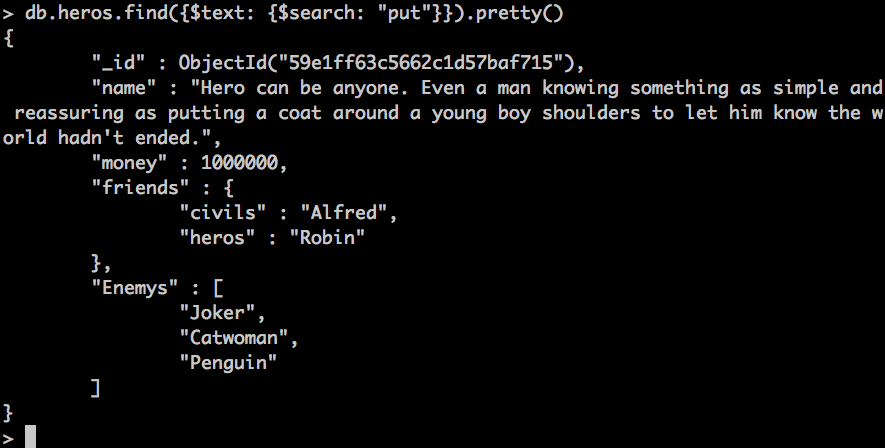
Un detalle es que el crea el índice en un idioma específico, por eso puede ignorar ciertas palabras (están soportados la mayoría de los idiomas) y en el caso de que no se le indicara el idioma en el índice, este seguiría siendo funcional pero no tan efectivo ya que nos metería palabras innecesarias en las búsquedas pero a grandes rasgos funcionaría perfectamente.
Como extra comentar que las búsquedas son caseInsensitive, es decir, ignora si la palabra está en mayúsculas o en minúsculas y también ignora los acentos (ambas opciones son modificables y lo veremos más abajo)
Importanto datos
Antes de continuar necesitamos una colección con algo más de información, para ello nos vamos a descargar una de ejemplo oficial de Mongo desde:
AQUI (recomiendo botón derecho- guardar como)
Ahora vamos a importarla, para ello nos salimos fuera de la shell de mongo y en la misma ruta donde hacíamos
bin/mongo
Ejecutamos lo siguiente
./mongoimport -c collectionTest -d databaseTest ../primer-dataset.json
Si no esta en esa ruta, buscar el ejecutable mongoimport, y lo que hacemos es meter los datos dentro de una colección nombre collectionTest que a su vez estará dentro de una base de datos llamada databaseTest (lo último es el fichero JSON que nos hemos descargado)
Veamos como son los documentos que tiene esta colección, usamos:
db.collectionTest.findOne()
Y veremos algo similar a esto:
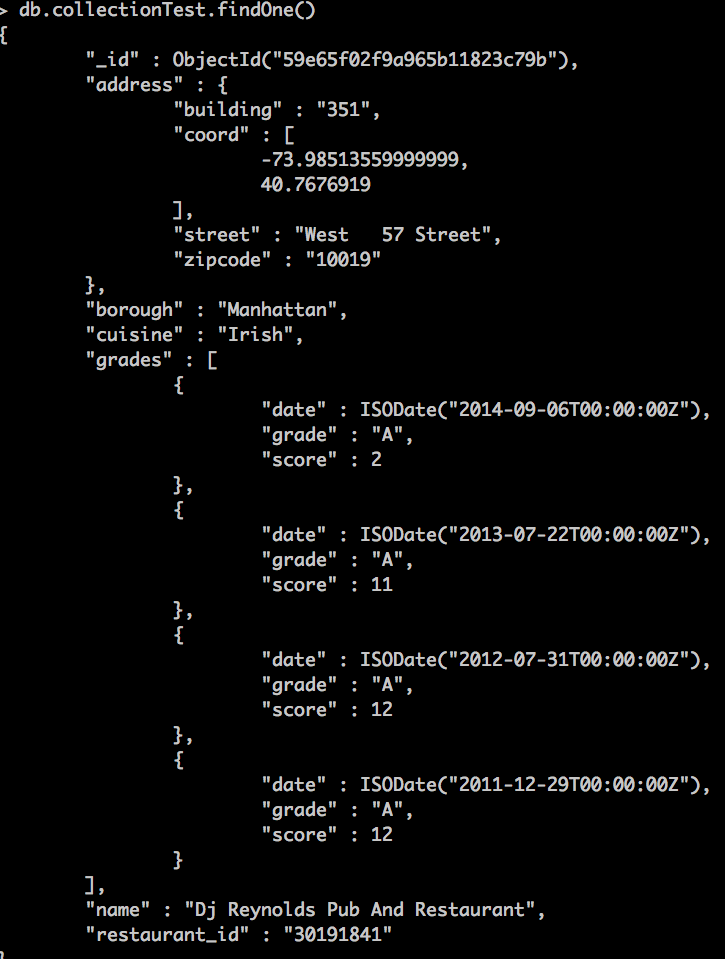
Tenemos coordenadas, que nos serán útiles cuando trabajemos con los índices geoespaciales, y tenemos varios campos de texto como "street", "name" o "cuisine". Con esto lo que vamos a ver es como podemos gestionar nuestros índices para que diferencie la importancia de unos campos de texto u otros y así poder hacer nuestras búsquedas más eficaces. Para ello tenemos la propiedad weights , que mejor que explicarlo creo que es verlo en un ejemplo de uso:
db.collectionTest.createIndex({name: "text","address.street": "text",cuisine: "text"},{weights:{name: 5, cuisine: 8, "address.street": 10}})
Si os fijáis hemos creado un índice con los tres campos que he comentado antes, y a continuación le he puesto unos pesos específicos a cada uno, cuanto más alto más importante es el campo. OJO para los subdocumentos es necesario poner comillas a los nombres de los campos en este caso sería el campo address:{ street}.
He puesto esos números pensando qué a lo hora de buscar un restaurante a no ser que busques un restaurante en concreto con el nombre exacto, sueles buscar una calle a ver que tiene, o lo mejor buscas por un tipo de cocina, pero esto es solo un ejemplo podéis usar la lógica que más os guste. En una aplicación en producción esto habrá que pensarlo más detenidamente.
Bueno ahora vamos a probar una búsqueda, y para que sea más visual vamos a solicitarle a Mongo que nos añada una puntuación a la búsqueda. Lo más fácil es verlo con un ejemplo:
db.collectionTest.find({$text: {$search: "irish"}},{score: {$meta: "textScore"}, name:1, cuisine:1, "address.street":1,_id:0}).sort({score:{$meta: "textScore"}})
Vayamos por orden:
- $text:{$search: "irish"}: Esto ya lo hemos visto que es la palabra por la que estamos buscando.
- score: {$meta: "textScore"}: Aquí le indicamos que nos genere un campo con la puntuación del texto.
- name:1, cuisine:1, "address.street":1,_id:0: Si os acordáis de esto, le estamos diciendo los campos que queremos ver para que no nos saque todos, name, cuisine y address.street, y ademas que nos quite el _id que nos molesta.
- sort({score:{$meta: "textScore"}}): Por último le decimos que nos ordene los resultados por la puntuación que ha recibido.
Al ejecutarlo obtenemos esto:
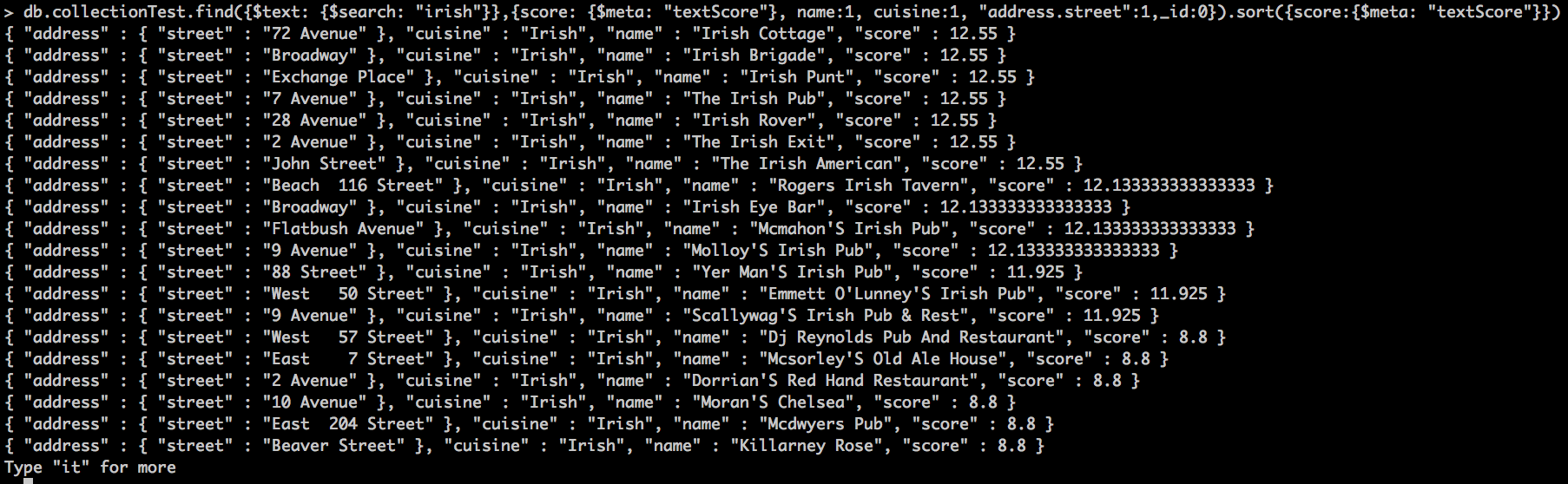
Vemos que obtenemos varios resultados (si escribimos it nos saldrán más) y que empiezan por 12.55 de puntuación. En este caso la puntuación es debida a que viene en cuisine y que ocupa gran parte del campo name si os fijáis va bajando la puntuación siempre que el campo name tiene más palabras(y no son comodines como The o a). Como detalle haceros a la idea de que estamos filtrando unos 25000 documentos que yo creo que no está nada mal lo que tarda en devolver los resultados
Bueno supongo que váis viendo un poco como funcionan las búsquedas de texto. Habréis visto que en el campo street no tenemos coincidiencias, vamos a buscar algo relacionado con una calle.
db.collectionTest.find({$text: {$search: "Jamaica"}},{score: {$meta: "textScore"}, name:1, cuisine:1, "address.street":1,_id:0}).sort({score:{$meta: "textScore"}})
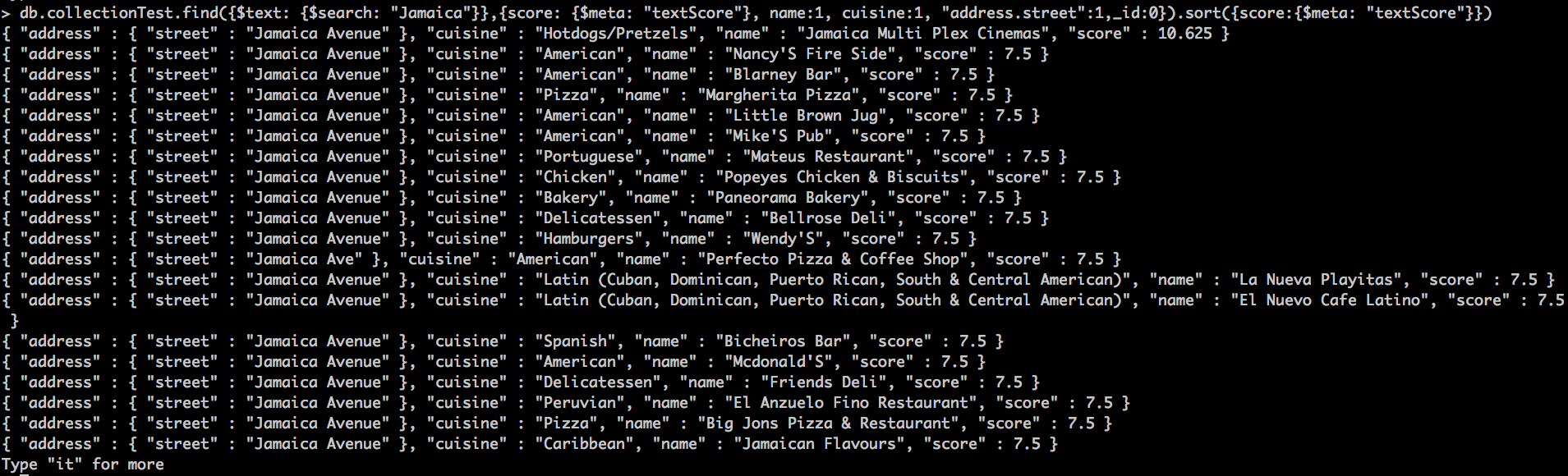
Veis que sigue el mismo concepto pero esta vez con la calle y el nombre. Estas búsquedas las podemos hacer tan complicadas como queramos igual que el resto que ya vimos anteriormente.
Como extra recalcar que podemos:
- Modificar el lenguaje del índice con $language: Idioma, por ejemplo
$languaje: Spanish
- Indicarle que sea $caseSensitive:
$caseSensitive: True (default false)
- Soportar acentos con $diacriticSensitive:
$diacriticSensitive: True (default false)
Creo que con esto es suficiente para que se entienda como funcionan los Full text index y podáis hacer los vuestros según requiera vuestra aplicación. Ahora empecemos con los Indices Geoespaciales
Geospatial Index
En Mongo tenemos dos tipos de índices Geoespaciales:
-
2d: Basicamente representa una cuadrícula sobre un plano, pensado para superficies pequeñas, por ejemplo un campo de fútbol. También si no tenemos pensado usar geoJSON o nos da igual la curvatura de la tierra.
-
2dsphere: El caso contrario, es decir, situamos cosas sobre la tierra. Este es el más común realmente. Esta basado en el estandar WGS 84, un estandar que intenta simular en una espera a la tierra.
Las posiciones en cualquier mapa están representadas por unas coordenadas, estas coordenadas están representadas en:
-
Latitud: Distancia desde el Ecuador al norte y al sur. De 0 a 90 al norte, de 0 a -90 al sur.
-
Longitud: Distancia desde el Meridiano de Greenwich (seían los 0 Grados). Para localizaciones al este sería de 0 a 180 y para localizaciones al oeste de 0 a -180
OJO las coordenadas en MongoDB se guardan Longitud/Latitud y en Google Maps Latitud/Longitud
Bien ya sabemos un poco de que hablamos, ahora veamos como crear un índice de este tipo:
db.collectionName.createIndex({campo_localización: "2dsphere"})
(Como véis siempre tiene el mismo estilo la creación de índices) Por si acaso no lo imagináis ya, el campo de localización tiene ser unas coordenadas o datos al estilo GeoJSON
Vamos a crear un índice con los datos de las coordenadas que tenemos en la colección que usamos antes, para ello basta con crear el índice:
db.collectionTest.createIndex({"address.coord": "2dsphere"})
Ya tenemos nuestro índice creado, ahora vamos a ver como es uno de nuestros elementos con coordenadas
db.collectionTest.findOne()
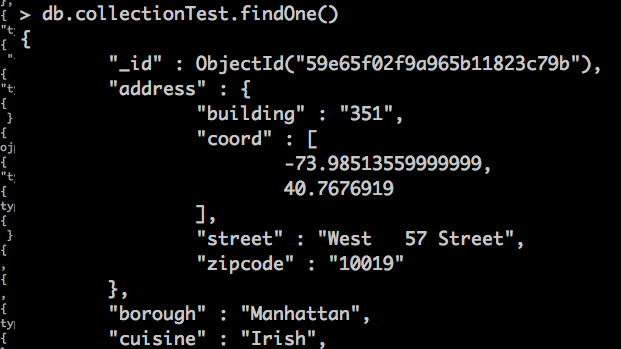
Y por si acaso nos vamos a ir a Google Maps a comprobar los datos, OJO recordad que están al revés
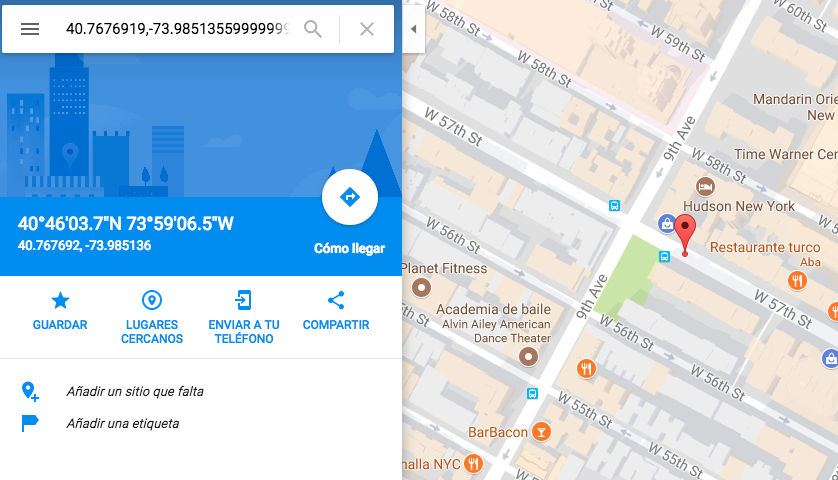
Coincide con nuestra calle ¿no?. Bueno pues ahora vamos a probar a buscar por coordenadas directamente, es decir, que me muestre quien contiene la coordenada que pasamos. OJO la búsqueda que vamos a realizar ahora lo que hace es buscar documentos que contengan esa coordenada, si tuvieramos una base de datos con las coordenadas de los paises enteros podríamos sacar el pais al que pertenece
db.collectionTest.find(
{"address.coord":
{$geoIntersects:
{$geometry:
{type: "Point", coordinates: [-73.9549067, 40.6971322]}}}},{"name":1}).pretty()
Veamos que estamos pidiendo aqui:
- address.coord: Esta es fácil le indicamos donde queremos que busque.
- geoIntersects: Es uno de los operadores para buscar con los índices Geoespaciales (tener en cuenta que todo esto esta más pensado para documentos tipo GeoJSON). En este caso lo que hace es buscar geometrias que se crucen con la coordenada que le indiquemos. Veremos alguno más, tenemos 4 distintos. Geospatial query operators
- geometry: Propiedad para indicarle lo que queremos buscar.
- type: Dentro de type le indicamos el tipo de coordenadas que le vamos a buscar, siempre pensando en formato GeoJSON. En este caso hemos puesto un tipo "Punto". Existen varios distintos, lo mejor es que los veáis en la documentación: GeoJSON Objects
- coordinates y name: Básicamente son las coordenadas por las que queremos buscar y lo que queremos que nos devuelva.
En este caso la búsqueda parece que es sobre una ubicación específica porque no tenemos coordenadas al estilo "Polígono", pero es más que nada para que veamos que funciona bien. Al ejecutarlo vemos que nos devuelve el restaurante que habíamos seleccionado

Probemos ahora algo con algo más de "chicha", vamos a buscar restaurantes que estén a unos 500 metros del que hemos seleccionado antes. Para ello en lugar de usar el operador geoIntersect vamos a usar el operador near
db.collectionTest.find({
"address.coord":{
$near:{
$geometry:{
type: "Point",
coordinates: [-73.9549067, 40.6971322]},
$maxDistance: 500
}
}
},{"name":1})
Como propiedad extra que no habíamos visto antes tenemos $maxDistance, en la cual indicamos una distancia máxima en metros.
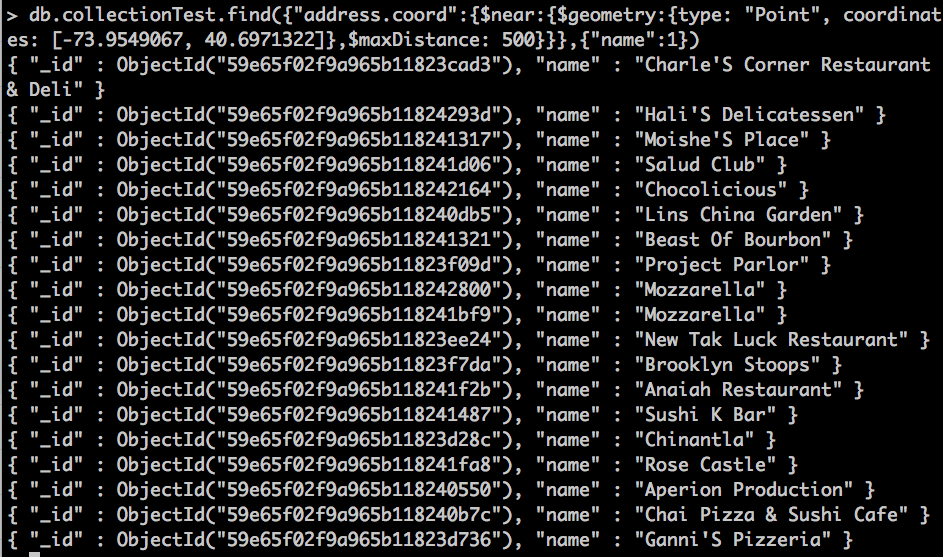
He cogido las coordenadas de los dos primeros restaurantes y si las ponemos en Google Maps (recordemos que tenemos que invertir las coordenadas ya que google las guarda al revés), y esto es lo que aparece
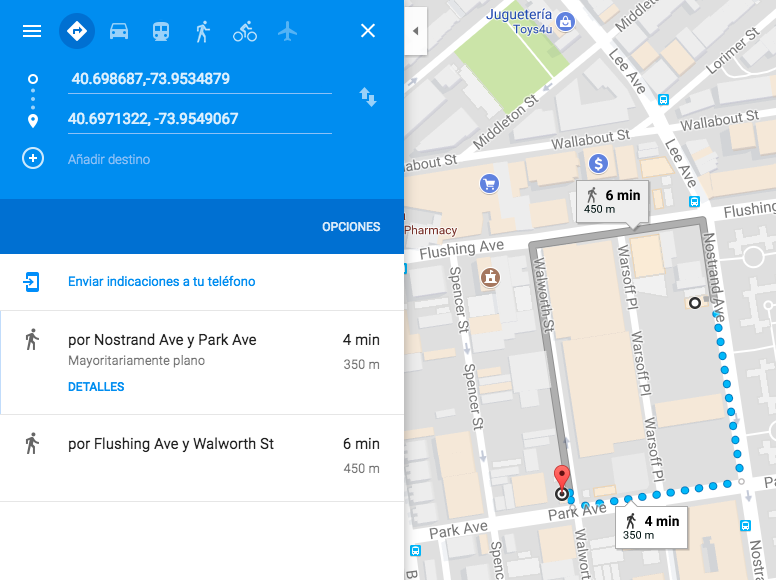
Como véis está a menos de 500 metros, por lo que podemos confirmar que realmente funciona.
Ahora pensemos en otro escenario, las aplicaciones móviles, en la mayoria de los casos cuando buscamos lo que tenemos alrededor en el mapa lo que queremos ver es que se vé en la pantalla, es decir, que hay en la cuadrícula del mapa que estoy mostrando. Esto también lo podemos hacer con MongoDB, solo tenemos que indicarle cuales son las coordenadas que se están mostrando actualmente.
db.collectionTest.find({"address.coord":{
$geoWithin: {
$geometry:{
type: "Polygon",
coordinates:[
[[-73,40],
[-75,40],
[-75,42],
[-73,42],
[-73,40]]]}}}},
{"name":1,"address.coord":1,"_id":0})
Si os fijáis en la query hemos cambiado la propiedad a geoWithin, es decir, lo que esté dentro de esa zona, y le pasamos un polígono, con 5 coordenadas (imagináos que es una línea que vamos dibujando, que empieza en un punto y tiene que acabar en el mismo punto, por eso son 5 ;) )
Aquí tendríamos una cuadrícula que sería más o menos esta zona
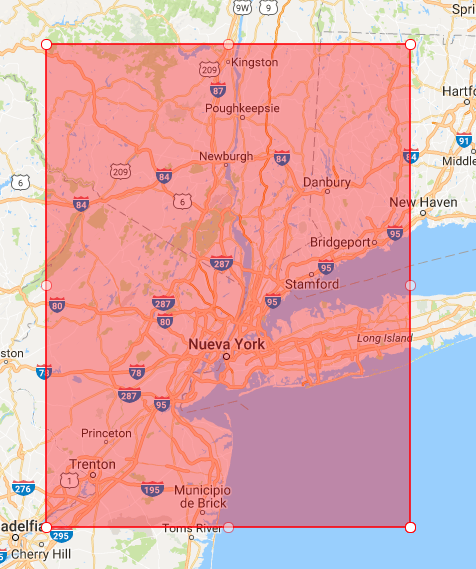
Si la ejecutamos veremos que nos saca un montón de coincidencias que son las que están dentro de esa zona (que yo diría que son todos jejeje)
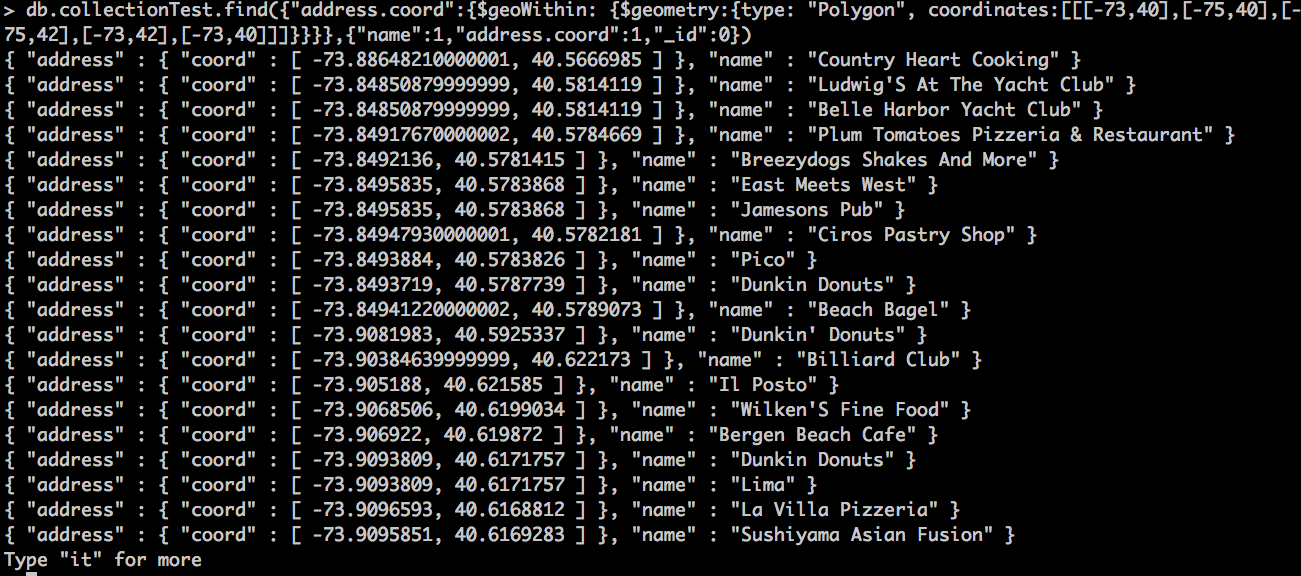
Si por ejemplo contamos los elementos:
db.collectionTest.find({"address.coord":{$geoWithin: {$geometry:{type: "Polygon", coordinates:[[[-73,40],[-75,40],[-75,42],[-73,42],[-73,40]]]}}}},{"name":1,"address.coord":1,"_id":0}).count()
Nos salen:

Vamos a probar a cambiar, todas las coordenadas -73 por -74 y así comprobamos como nos filtra de verdad:
db.collectionTest.find({"address.coord":{$geoWithin: {$geometry:{type: "Polygon", coordinates:[[[-74,40],[-75,40],[-75,42],[-74,42],[-74,40]]]}}}},{"name":1,"address.coord":1,"_id":0})
Si ejecutamos vemos como todos los documentos empiezan a partir de la longitud -74
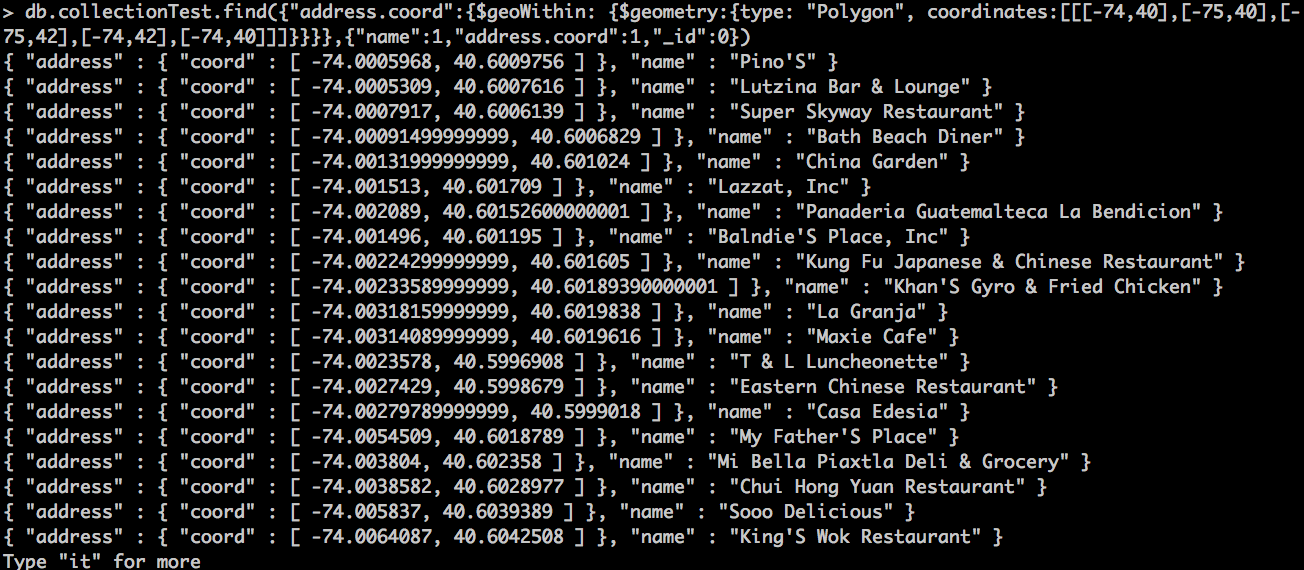
Si contamos ahora los documentos tenemos

Como vemos realmente si nos está filtrando por una zona en específico. Esto es un ejemplo de algunas cosas típicas que podemos necesitar hacer.
Subiendo de nivel
Bien ahora subamos un poco más el nivel, vamos a ver como podemos programar directamente en la consola de MongoDB, en este ejemplo que vamos a ver seguiremos usando los índices geoespaciales porque son los últimos que hemos visto, pero tener en cuenta que se podría hacer como queráis.
Lo que vamos hacer va a ser recorrer todos los restaurantes que tenemos en la colección de test que estamos usando y vamos a ponerles una propiedad nueva indicando cual es el primer restaurante que esté a menos 500 mt (si hay alguno claro).
Una cosa muy interesante y util en mongo es que podemos usar variables.....y bueno podemos usar un estilo de programación similar al de JavaScript. Entonces para este ejemplo vamos a usar el siguiente código (podéis copiar y pegar ;) )
var restaurants = db.collectionTest.find()
while(restaurants.hasNext()){
var rest = restaurants.next();
var coords = rest.address.coord;
if (coords != ""){
var neighbour = db.collectionTest.find({"address.coord":{$near:
{$geometry:{type: "Point", coordinates: coords},$maxDistance: 500}}}).skip(1).limit(1);
if (neighbour[0] != undefined){
var neigh = neighbour[0];
db.collectionTest.update({"_id": rest._id},
{$set: {
"address.neighbour": neigh.name
}}
);
}
}
}
En general supongo que más o menos se entiende el código (y no está con la intención de ser el mejor ni el más bonito solo es un ejemplo) pero por si acaso voy a explicarlo paso a paso.
Lo primero almacenamos todos nuestros documentos en una variable, se podría haber limitado la cantidad o cualquier cosa que se os ocurra pero así comprobamos lo que tarda en modificarnos mas de 25000 documentos.
var restaurants = db.collectionTest.find()
Y a continuación por ejemplo haremos un bucle while recorriendo los documentos que tenemos almacenados en la variable restaurants
while(restaurants.hasNext()){
Almacenamos el documento en cuestión y las coordenadas de que tiene ese documento:
var rest = restaurants.next();
var coords = rest.address.coord;
Tenemos algunos documentos que tienen la propiedad coord vacía por lo que lo comprobamos
if (coords != ""){
Lo siguiente será buscar cuál es el restaurante más cercano, sin ser el propio restaurante propietario de esas coordenadas, al buscar por coordenadas nos identifica el primero como el propio restaurante, por eso ignoramos el primer resultado. Y como solo queremos encontrar uno de "los vecinos" limitamos la búsqueda a 1
var neighbour = db.collectionTest.find({
"address.coord":{
$near:{
$geometry:{
type: "Point",
coordinates: coords}
,$maxDistance: 500}}}).skip(1).limit(1);
Como es posible que no tengamos nungún documento(restaurante) a menos de 500 metros tenemos que comprobar antes de hacer nada para que el proceso continue
if (neighbour[0] != undefined){
Y por último actualizamos el restaurante usando el "_id" añadiendole la propiedad "address.neighbour" con el nombre del restaurante vecino
db.collectionTest.update({"_id": rest._id},
{$set: {
"address.neighbour": neigh.name
}}
);
El proceso tardará un rato, y una vez terminado, si buscamos algún documento
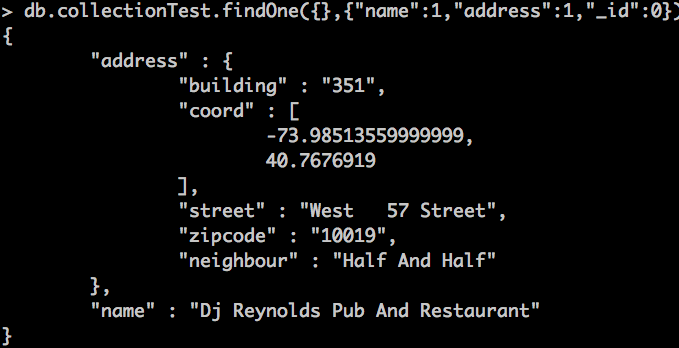
db.collectionTest.findOne({},{"name":1,"address":1,"_id":0})
Veremos como nos ha añadido una nueva propiedad con el nombre de algún restaurante cercano
Esto es solo un pequeño ejemplo de lo que podemos hacer con MongoDB, podemos complicar las búsquedas tanto como queramos (aunque lo suyo es que una parte lo hiciera nuestra app no la base de datos sola ;) )
Espero que con este post seais capaces de mejorar vuestros índices y hacer que vuestras búsquedas en vuestras bases de datos MongoDB sean mucho más eficientes. De momento vamos a dejar el tema de los índices, lo próximo que veremos será el Aggregation Framework, si no sabéis lo que es no os preocupeis lo veremos en detalle. Nos veeemoosssss un abrazooorrrrrr