

Antes de nada voy a comentar sobre una duda que surgió hace poco en mi entorno (y aprovechando que este post es más corto lo meto aquí), ¿qué es el journal?. Para el que no sepa de que hablo si miramos en el filesystem donde se está almacenando nuestra base de datos tenemos una carpeta journal
Esta carpeta es una colección especial de Mongo en la que se almacenan los datos temporalmente antes de pasar a nuestro disco duro de forma definitiva. Es un mecanismo de salvaguarda en caso de que nuestro proceso se caiga en medio de algo. Es decir, mongo tiene un proceso que por defecto cada 60 segundos o cada 2GB de journal pasa los datos al disco si no han sido pasados antes.
Esto se puede ver cuando arrancamos mongo

Si os fijáis en esa línea, entre otras cosas nos aparece esta línea
log=(enabled=true,archive=true,path=journal,compressor=snappy)
Donde indica donde mete los datos de log (que sería el journal), y también tenemos esta otra
checkpoint=(wait=60,log_size=2GB)
Que nos índica cada cuanto hace un guardado en disco (cada 60 segundos si no ha escrito o cuando el log llegue a 2GB), pues el journal sería una colección muy ligera que esta guardando los datos cada 100 ms, por lo que en el caso de que nuestro servidor se caiga entre checkpoints y no tuvieramos los últimos cambios en el disco, si los tendríamos en el journal.
Documentos en MongoDB
Hemos comentado que Mongo es una base de datos orientada a documentos (ya lo comentamos por encima jejeje), estos documentos realmente son objetos JSON. Estos se almacenan codificados en un formato específico conocido como BSON (Binary JSON), los almacena de forma eficiente y nos evita el tener que parsear los documentos, simplemente trabajamos con ellos en su propio formato. Por eso es tan eficiente en las búsquedas.
Scheme
Empecemos a comentar cosas sobre el scheme, en Mongo no tenemos un esquema definido pero aún así es algo que tenemos que pensar antes de empezar a trabajar Mongo. Todo se basa siempre en lo mismo: tiempos de lectura, es decir tenemos que intentar que para obtener los datos, imaginemos que de este mismo blog, de una de las páginas lo podamos hacer en una única query, ya que en Mongo esto es lo que haría realmente eficiente nuestro esquema. Ya hemos visto lo que tarda realmente en hacer búsquedas de muchos elementos en una sola query (como el ejemplo de los 1000000 elementos del post anterior), si en lugar de hacer una búsqueda única tenemos que mezclar varias querys el tiempo que tardaríamos en mostrar una página sería bastante más alto.
Y pensando en esto es como tenemos que definir nuestros scheme ficticio, ¿que información voy a necesitar en cada momento?. Para explicar esto lo voy a poner con ejemplos similares a los que yo lo aprendí, pensemos otra vez en un blog. Un post de un blog normalmente tiene estos elementos:
- Titulo
- Autor
- Fecha de publicación
- Texto del post
- A lo mejor tiene tags
- Comentarios
Más o menos esos son los elementos que podríamos decir "básicos" en la mayoría de los post del mundo. Entonces siguiendo la teoría de lo que hemos dicho de cada documento tiene que tener toda su información para poder traerla en una query un ejemplo de post sería este:
{
"post_id": 12334,
"post_title": "Titulo de Post",
"author": "Juan Luis Garcia",
"publish_date": "11-11-1111",
"post_text": "Un montón de palabras juntas contando algo",
"tags":["tag1","tag2","tag3"],
"comments":[{
"comment_author": "Superman",
"comment_date": "12-12-1212",
"comment_text": "Esto es un supercomentario"
},{
"comment_author": "Batman",
"comment_date": "13-13-1313",
"comment_text": "¡¡Soy Batman!!"
},
{...},{...},{...}]
}
Más o menos podría tener sentido, ¿no? pero claro....el tema de los comentarios.......al final según el post podríamos tener un documento gigante y para recorrerlo en busca de algo.....o supongamos que tenemos un montón de comentarios en todos los posts......uffff.....demasiado para que la gestión sea realmente eficiente, planteemonos lo siguiente ¿qué es lo que mostramos realmente en el post? ¿mostramos todos los comentarios que tenemos? ¿O realmente tenemos un límite de los que mostramos y luego si el usuario quiere ya pide más?.... realmente el escenario normalmente es este último ¿verdad?...bien, pero ¿qué hacemos con el resto de nuestros comentarios?...fácil lo que hacemos es linkarlos, es decir, establecer algún tipo de relación con alguna propiedad.
Vamos paso a paso, primero hemos dicho que tenemos un límite de los post que mostramos inicialmente...supongamos que mostramos 5, entonces no cambia lo que teniamos antes, simplemente que controlamos que tenga 5. Eso lo hacemos con código realmente, es decir depende del cliente...pero y si ya tiene 5, ¿qué hacemos?...alguno pensará que tenemos que hacer una query para eliminar y otra para añadir.....pero realmente no es necesario, tal como es el lenguaje podemos hacer las 2 operaciones en la misma query aprovechandonos de la misma búsqueda
db.blog.update({post_title: "Algo"},{$pop:{comments:1},$push:{comment:.....}})
Con $pop eliminamos o el último o el primero según queramos y como ya hemos visto con $push añadimos nuevos elementos. Como vemos esta operación realmente puede ser ínfima o tener un precio mínimo, perfecto...y teniendo un límite de 5 comentarios podemos gestionar los documentos de post de una forma bastante eficiente.
Ahora lo siguiente, ¿que hacemos con el resto de los post?, bien lo ideal es tenerlos en otra colección donde hagamos referencia al post en cuestión, por ejemplo
{
"comment_id": 41325,
"post_id": 12334,
"comment_author": "Superman",
"comment_author_email": "superman@correo.com",
"comment_date": "12-12-1212",
"comment_text": "Esto es un supercomentario"
},
{
"comment_id": 41326,
"post_id": 12334,
"comment_author": "Batman",
"comment_author_email": "batman@correo.com",
"comment_date": "13-13-1313",
"comment_text": "¡¡¡Soy Batman!!!"
}
Cuando el usuario pida más comentarios solo tenemos que buscar por el post_id y listo, ya tendríamos todos los comentarios que necesitamos y si os fijáis al separarlo de esta manera tenemos la posibilidad de añadirle más información a los comentarios por si la necesitamos.
Esto es solo un ejemplo de como podemos establecer relaciones en nuestras bases de datos simplemente teniendo una propiedad que relacione ambas, esto se puede complicar tanto como sea necesario, lo único siempre pensar en como se va a trabajar realmente en nuestra aplicación, cuales van a ser las querys que se van a realizar o cuales son las que necesitamos para que sea lo más eficiente posible.
A parte de esto tenemos que ver la posibilidad de gestionar un poco el no scheme, es decir, ¿como evitamos que se cambie el esquema si Mongo acepta cualquier cosa que le pasemos mientras tenga un formato JSON correcto?....bueno aquí tenemos dos entornos que podemos gestionar el de la aplicación cliente y el propio de MongoDB.
En cuanto a la aplicación cliente poco que decir, más que realmente la responsabilidad del modelo de los documentos tenía que estar en el cliente ya sea controlándolo a mano o con modeladores de objetos específicos de cada lenguaje, como puede ser Mongoose en NodeJS (lo usaremos más adelante).
MongoDB con el tiempo, debido a peticiones de la comunidad añadió a finales de 2015 (si no me equivoco) su propio validador de documentos. Básicamente nos permite controlar qué se inserta o se actualiza en nuestra base de datos, hagamos un ejemplo sencillo solo para que veais un poco funcionaría lo ideal es que miréis la documentación oficial para ver todo lo que podemos hacer con esto. Comentar también que esto debería ser como una segunda comprobación, que exista esta opción no hace que no sea necesaria la opción de controlar los objetos en las aplicaciones cliente.
Vamos a comprobar por ejemplo que en nuestro campo money solo podamos insertar números, ahora mismo tal como lo teniamos podemos insertar propiedades de tipo string sin problemas
db.heros.insert({name: "Deadpool", money: "one hundred"})
Si ahora buscamos a Deadpool y a Black Panther vemos como cada uno tiene un campo money distinto:

Para evitar creamos un validator de los datos de una colección ya existente de esta forma:
db.runCommand({collMod: "heros",validator: {money: { $type: "number"}}})
En collMod le estamos indicando la colección que queremos modificar y como validador le indicamos que el campo money tiene que ser de tipo number.
Ahora si intentamos insertar un documento nuevo con el campo money como string
db.heros.insert({name: "Wolverine", money: "two hundreds"})
Obtenemos este resultado
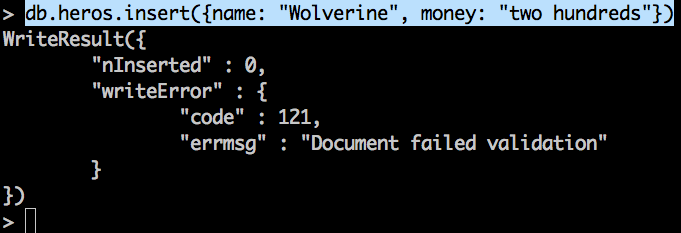
Tenemos, si o si, que pasarle los datos en el formato que los solicita
db.heros.insert({name: "Wolverine", money: 200})
Para que realmente los inserte en la base de datos

Estas reglas de validación las podemos hacer tan complejas como queramos, podemos usar expresiones regulares, dar opciones de datos específicas.......lo que he comentado mirar la documentación oficial sobre el tema y vereis que podéis hacer.
Comentar que podemos crear las reglas de validación junto con la creación de la colección
db.createCollection("heros2",{validator: {money: { $type: "number"}}})
Y ya de paso si cremos así la colección nos aparece directamente sin insertar ningún dato, y tenemos también nuestra regla de validación desde el principio.
Bueno hasta aquí el post sobre vivir con no scheme, como véis no tenemos un modelado de esquemas al estilo relacional pero creo que entre el poder linkar colecciones usando algun campo como referencia y con los validators podemos trabajar casi en cualquier entorno que queramos con esta base de datos.
En el próximo post veremos como hacer algunos índices mas complejos como las de geolocalicación.
Nos vemos en el siguienteeee un abrazooorrrrrr