

Antes de nada tenemos un repo con un script para insertar los documentos que usamos de ejemplo:
En general sabemos que es un índice de mongo pero hablemos un poco más en profundidad. Si no índicamos un índice cuando creamos una colección mongo, por defecto, nos creará un índice con el campo _id de tipo único (no se puede repetir el campo).
Cuando creamos un índice mongo crea otra especie de mini colección solo con los datos que le indicamos en el índice, ordenados de la manera que le indiquemos y apuntando al documento al que hacen referencia. Cada índice tiene una especie de firma, es decir, se le asigna un nombre para identificarlo usando los campos del índice y mongo recorre su lista de indices hasta que encuentra una coincidencia, es decir, si buscamos por dos campos intentará encontrar uno donde coincida la firma de esos campos y si no busca separando los campos hasta que encuentra una coincidencia, si no la encuentra continuará con una búsqueda sin índice.
Pero antes de ver esto vayamos paso a paso.
Mongo sigue la misma teoría que el resto de bases de datos con sus índices, usa lo que se conoce como Binary Tree Sort, es un tipo de algoritmo de búsqueda bastante eficiente para estas cosas Más info
Sintaxis básica de creación de índices
Antes de ver los tipos de índices la sintaxis básica de creación de índices es la siguiente
db.getCollection('index').createIndex({lastName: -1})
Siendo lastName el campo del que queremos el índice y -1 es la ordenación si lo queremos ascendente pondremos un 1, si lo queremos descendente -1
Más adelante veremos las opciones de creación de los índices.
Tipos de índices
Single field (un solo campo)
Como dice el nombre tenemos un tipo de índice donde lo creamos solo con un campo, es decir:
db.getCollection('index').createIndex({lastName: 1})
Veamos un ejemplo con la diferencia de tener un índice a no tenerlo. En la colección de prueba que tenemos vamos a realizar un búsqueda por lastName y veamos lo que tarda. Busquemos con el siguiente comando primero en la colección sin índice:
db.getCollection('noindex').find({ lastName: 'Master'}).explain("executionStats")
Esto nos da que nos ha traido 10 elemento en un tiempo de 4190 ms

Ahora vamos a crear un índice en la colección para ello con este comando:
db.getCollection('index').createIndex({ lastName: 1 })
(más adelante veremos como ver los índices que tenemos y cosas así)
Ahora ejecutemos la misma búsqueda pero dentro de la colección con índice que acabamos de crear:
db.getCollection('index').find({ lastName: 'Master'}).explain("executionStats")
Esto nos da que nos ha traido 10 elementos en un brutal tiempo de 10ms la primera vez y las siguientes a 0ms

Ahora se puede ver un poco la potencia que nos proveen los índices.
Veamos otro ejemplo que no va también, vamos a crear primero un índice de un campo con esto:
db.getCollection('index').createIndex({ city: -1 })
Tenemos una colección donde la gran mayoría de los 2000000 de elementos tienen la misma ciudad, por lo que ahora pasa una cosa curiosa, veamos la búsqueda con indice
db.getCollection('index').find({ city: 'Madrid'}).explain("executionStats")
Tarda unos 8873ms, ahora veamos la búsqueda normal

db.getCollection('noindex').find({ city: 'Madrid'}).explain("executionStats")
Sorprendentemente tarda 3963ms mucho menos

Pero porqué?? Bueno el algoritmo de búsqueda binaria que tienen los índices no es eficiente para este tipo de colecciones donde la mayoria de elementos son iguales, para que este algoritmo haga su magia necesitamos que los elementos a buscar sean la mayoría diferentes, por eso en este caso es más eficiente la búsqueda habitual donde recorre todos y descarta los que no necesita.
Si tenemos esta casuística donde un montón de campos son iguales lo más probable es que filtremos por algún campo más, es decir que creemos un índice de tipo compound (los veremos a continuación), pero si quisieramos realizar una busqueda sin índice, en mongo se conoce como búsqueda natural y aunque no se suele comentar esto mucho por los mares digitales, tenemos la posibilidad de forzarlo, solo tenemos que sugerirlo de esta manera:
db.getCollection('index').find({ city: 'Madrid'}).hint({ $natural : 1 }).explain("executionStats")
hint es uno de los extras que podemos indicar en las busquedas para sugerir un índice u otro según el nombre, podemos ponerlo de la misma manera que pusimos al crear el índice:
db.getCollection('index').find({ city: 'Madrid'}).hint({ city: -1 }).explain("executionStats")
O con el nombre de índice que se crea:
db.getCollection('index').find({ city: 'Madrid'}).hint("city_-1").explain("executionStats")
Los podemos ver por ejemplo desde robo3t
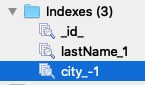
Visto este caso especial pasemos a los índices compuestos donde podemos ver búsquedas eficientes por varios campos
Compound fields (compuesto....o básicamente varios campos)
Los siguientes índices son los que involucran a varios campos dentro de nuestras colecciones, estos siguen un orden según como los escribamos, la sintaxis básica sería:
db.getCollection('index').createIndex({ field1: 1 , field2: -1})
Lo que hace este índice es crear un índice partiendo principalmente del field1 con un orden ascendente y dentro de los field1 que coincidan los ordena según el field2 de manera descendente.
En nuestro caso crearemos un índice por ciudad e email, recordemos que en ciudad tenemos 1999000 veces la misma ciudad y antes ha tardado mogollón
db.getCollection('index').createIndex({ city: -1, email: 1 })
Ahora veamos la búsqueda sín indice:
db.getCollection('noindex').find({ city: 'Madrid', email: 'NinjaMaster@email.com'}).explain("executionStats")
Ha tardado 5112ms que no está nada mal pensando en la búsqueda anterior, pero ahora veamos la búsqueda con el índice

db.getCollection('index').find({ city: 'Madrid', email: 'NinjaMaster@email.com'}).explain("executionStats")
Sorprendetemente ha tardado solo 12ms

Cosas que tenemos que tener en cuenta de los índices compuestos:
- Tienen un límite de 32 campos
- En un principio el orden en que definamos el índice no influye demasiado (menos en los $fullText que usaría como filtro inicial para hacer el de texto) a la hora de buscar pero si a la hora de ordenar nosotros añadiendo un sort a continuación del find. Partiendo del índice que hemos definido anteriormente no seria lo mismo hacer esto:
db.getCollection('index').find({ city: 'Madrid', lastName: 'Master', email: 'NinjaMaster@email.com'}).sort({ city: -1, email: 1 }).explain('executionStats')
Que hacer esto:
db.getCollection('index').find({ city: 'Madrid', lastName: 'Master', email: 'NinjaMaster@email.com'}).sort({ email: 1, city: -1 }).explain('executionStats')
O esto:
db.getCollection('index').find({ city: 'Madrid', lastName: 'Master', email: 'NinjaMaster@email.com'}).sort({ city: 1, email: 1 }).explain('executionStats')
La primera usa el índice directamente y no tiene que hacer nada más:
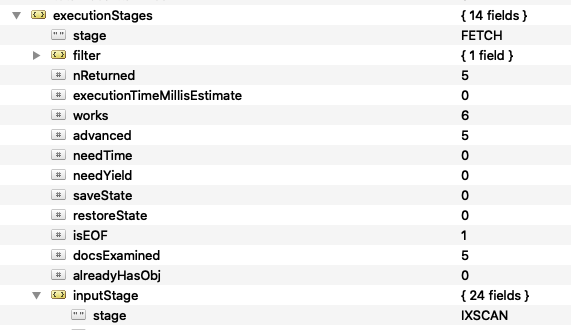
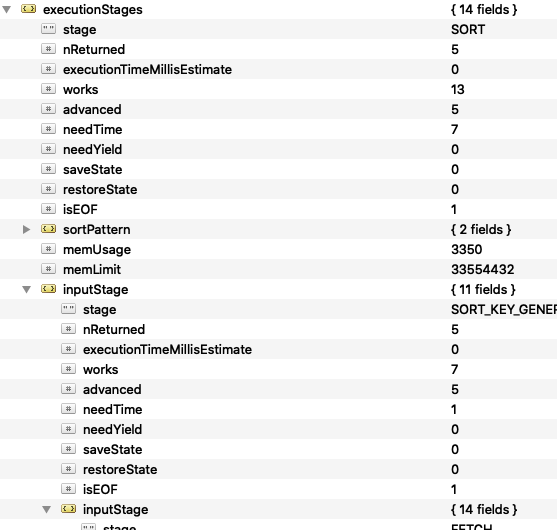
Las otras dos pasan del índice para hacer la ordenación, la segunda porque directamente ordenamo primero por email y la segunda porque no es ninguna de las opciones factibles en cuanto a dirección un índice usa solo dos tipos de ordenaciones: la misma con la que se ha definido y la que es directamente opuesta, es decir, si definimos un índice con 1,-1,1, usaría el índice para ordenar bajo esa definición o con -1,1-1
Multikey Index (Indice con arrays en resumen)
Este tipo de índice lo crea automáticamente mongo al detectar un campo de tipo array, en un principio podemos pensar que no tiene mucho de especial, pero realmente tenemos que tener en cuenta que el índice creará una entrada por cada elemento del array. Supongamos que además de ciudades tenemos un array de poblaciones donde por ejemplo puede trabajar ese usuario, si alguien de Madrid tiene de poblaciones disponibles Coslada, Vicalvaro, Mordor.... nos creara:
Madrid + Coslada
Madrid + Vicalcaro
Madrid + Mordor
...
Esto es importante a la hora de controlar el tamaño del índice, los índices ocupan espacio.....por si no lo habías pensado y también consumen al rehacerse, cada vez que se escribe se vuelve a indexar
A tener en cuenta:
- Solo podemos tener índices con uno de los valores de tipo array, si intentamos tener dos nos dirá que nos dediquemos a la pintura
- Si tenemos un índice con array e intentamos insertar en otro de los campos del índice un array nos dirá otra vez que lo nuestro es el arte
- Podemos crear índices con campos con arrays de documentos, que funcionarían igual que los arrays normales si le indicamos uno de los campos del documento
db.getCollection('index').createIndex({ 'tags.front': -1 })
db.getCollection('index').find({ 'tags.front': 'Vuejs' }).explain('executionStats')
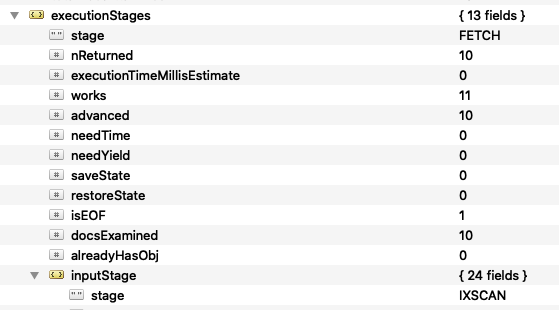
Si no le indicamos un campo en concreto nos creará un índice pero solo funcionara con documentos completos, no con campos específicos. Borramos el índice anterior y creamos este:
db.getCollection('index').createIndex({ 'tags': -1 })
Ahora realizamos la misma búsqueda anterior:
db.getCollection('index').find({ 'tags.front': 'Vuejs' }).explain('executionStats')
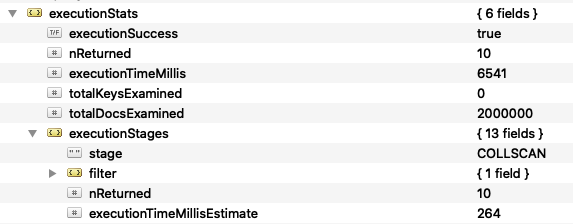
Lo notamos con el tiempo que tarda pero podemos vemos como hace la búsqueda básica con COLLSCAN.
Sin embargo si búscamos un documento al completo:
db.getCollection('index').find({ 'tags': {
front: 'Vuejs',
back: 'Node'
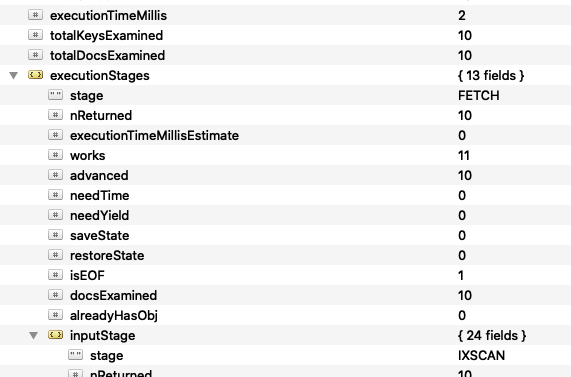
} }).explain('executionStats')
Vemos como tarda bastante menos y además nos indica que ha usado un índice
Indice Full text(o campos con un montón de texto)
El índice de texto es un tipo de indice especial que nos mejora la búsqueda con un conjunto de palabras sobre un número n de campos, es decir, nos busca en todos los campos que tenga el índice. Este índice se puede aplicar en cualquier campo de tipo string o de array con valores de tipo string, donde podemos indicarlo el idioma en cuestión para que ignore palabras comunes como 'y, o, de' en español.
Por defecto se crea con idioma inglés por lo que en nuestro caso lo añadiremos a la hora de la creación del índice.
Para hacernos una idea de que tiene de especial, los índices habituales lo que hacen es crearlo basandose en esto que buscas está en estos documentos, sin embargo este tipo de índice lo que hace es darle la vuelta este documento tiene estas palabras
En este caso los ejemplos son un poco más complicados, las búsquedas especiales por un texto solo funcionan si tenemos un índice, por lo que , por ejemplo, en la colección noindex no podremos hacer esta búsqueda, lo más parecido sería una expresión regular con un find sobre los campos que quisieramos realizar la búsqueda y evidentemente tardará un poco más, veamos un ejemplo. Para la pruebas tener en cuenta que no seria lo mismo que un entorno de producción esto es solo para entender los conceptos, en un entorno real puede tardar más o menos la búsqueda sin índice:
db.getCollection('noindex').find({ firstName: /Juanchu/,
alias: /Juanchu/,
bio: /Juanchu/ }).explain("executionStats")
Esto nos da un tiempo de 4429ms que no está nada mal.
Creemos ahora un índice con los campos en formato texto:
db.getCollection('index').createIndex({ bio: 'text', firstName: 'text', alias: 'text' }, { default_language: "spanish" })
Esto tardará un montón, es un índice que tiene que comprobar todas las palabras que tienen nuestros campos de texto, y si no le ponemos el idioma bien....pues más todavía porque almacenará palabras innecesarias.
Ahora que ya tenemos el índice busquemos el mismo concepto:
db.getCollection('index').find({ $text: { $search: "Juanchu" } }).explain("executionStats")
Ahora vuelve a tardar 1ms, bastante mejor ¿no?. En un entorno con más campos se notaría más la diferencia

Para que veamos lo que nos ha encontrado
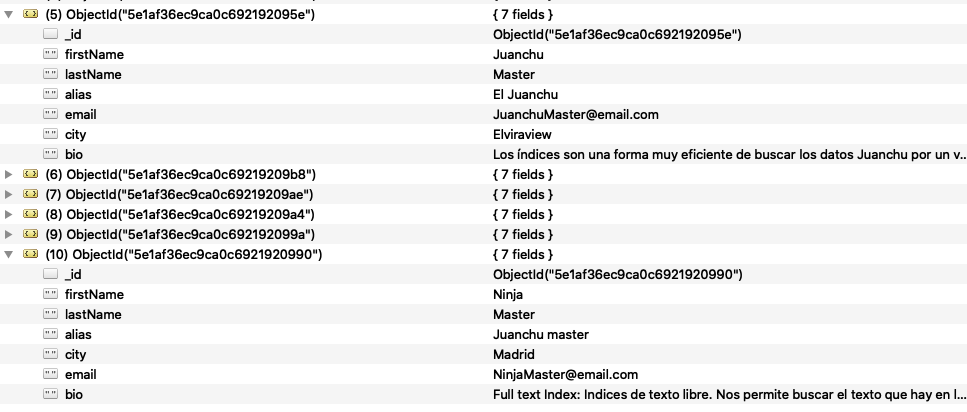
Con esto tenemos un ejemplo, veamos ahora que epecialidades tenemos con este tipo de índice:
- SOLO ES POSIBLE TENER UN ÍNDICE DE TIPO TEXT, es decir, si queremos añadir campos de texto, tenemos que eliminar el que tuvieramos y hacerlo de nuevo.
- Es CASE-INSENSITIVE
- Se le pueden indicar pesos de importancia a cada campo, esto sumará las veces que aparece la palabra que buscamos en cada campo y documento y nos los devolverá según ese orden si se lo indicamos en la busqueda.
Creación:
db.getCollection('index').createIndex(
{
alias: "text",
bio: "text",
firstName: "text"
},
{
weights: {
firstName: 10,
alias: 5
}
},
{ default_language: "spanish" }
)
Esto crearía un índice con los pesos:
* firstName 10
* alias 5
* bio 1 (by default)
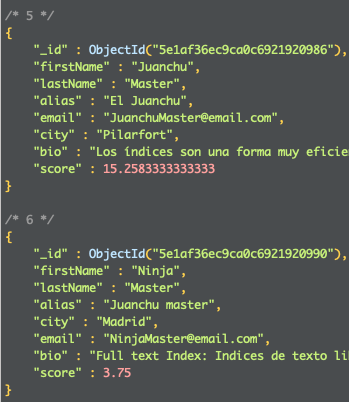
db.getCollection('index').find(
{ $text: { $search: "Juanchu" } },
{ score: { $meta: "textScore" } }
).sort( { score: { $meta: "textScore" } } )
- Los Wildcard indices o índices creados según un patrón de posibles campos, aquí solo podemos ponerlo una vez y lo que haría sería un índice con todos los campos de tipo string (más adelante veremos esto de los wildcard)
- Sí no queremos hacer que ignore las palabras tipo
y, o, deque las usa como delimitadores para conjuntos, podemos índicarlelanguage: "none" - No se puede indicar
hintpara sugerir un índice a la hora de realizar búsquedas tipo text - En los índices compuestos podemos tener varios campos de tipo text pero solo podemos tener el resto de campos tipo single, es decir, no podemos tener
multikeys o geospatial - Crear este tipo de índice es muy costoso a nivel de recursos, tanto en ram como en espacio y puede hacer más lenta la inserción de nuevos campos que esten bajo ese índice.
Índice de texto multiidioma
Esta parte require su propio título ya que tiene un poco de miga. Podemos tener colecciones en multiples idiomas y para mejorar la búsqueda bajo estos campos podemos modificar un poco los campos del documento para que mongo haga su magia con las búsquedas, añadiendo solo la traducción pertinente según el idioma que le indiquemos en el índice.
Para esto tenemos que tener un campo language donde indiquemos el lenguaje en cuestión del documento o campo, así a la hora de hacer el índice mongo sabra mejor que tiene que hacer con ese campo. Un ejemplo de documento podría ser este:
{
_id: 1,
language: "portuguese",
original: "A sorte protege os audazes.",
translation:
[
{
language: "english",
quote: "Fortune favors the bold."
},
{
language: "spanish",
quote: "La suerte protege a los audaces."
}
]
}
Si quisieramos tener otro campo como indicador de lenguaje lo podemos indicar a la hora de crear el indice:
db.quotes.createIndex( { quote : "text" },
{ language_override: "idioma" } )
Wildcard Index (indices sin saber los campos...)
Esto no es muy dificil de entender, queremos crear índices donde el nombre de los campos puede ser dinámico, es decir, puede ir cambiando como puede ser un campo con metadatos que pueden ir variando, en este caso por ejemplo creariamos un índice así:
db.getCollection('index').createIndex( { "user_metadata.$**" : 1 } )
Esto nos crearía un indice teniendo en cuenta que dentro de user_metadata podemos tener de todo tipo de campos:
{
user_metadata: {
"clicks": 200,
"views": 1000
}
},
{
user_metadata: {
"images": 500,
"favorite_tags": ["games", "dogs"]
}
}
Si queremos crear un índice por todos los posibles campos, simplemente
db.getCollection('index').createIndex( { "$**" : 1 } )
Un índice de tipo wildcard recorrera todos los nested documents que se encuentre
También es posible indicar este tipo de índice en campos específicos
db.collection.createIndex(
{ "$**" : 1 },
{ "wildcardProjection" :
{ "user_metadata" : 1, "games.rewards_info" : 1 }
}
)
Para hacerlo usamos wildcardProjection como indicador de lo que queremos hacer. Esto por ejemplo nos haría un índice con todo lo que estuviera dentro de esos dos campos.
También podemos excluir campos:
db.collection.createIndex(
{ "$**" : 1 },
{ "wildcardProjection" :
{ "user_metadata" : 0, "games.rewards_info" : 0 }
}
)
- Por defecto este tipo de índice omite el campo
_id, si queremos añadirlo solo tenemos que indicarlo dentro dewildcardProjection - No es posible crear indices compuestos usando wildcard
- No pueden ser indices únicos ni tener TTL
- No pueden ser Geoespaciales o Hashed
- Si queremos ordenar con este tipo de índice solo podemos hacerlo usando el campo mediante el que busquemos, es decir, si usamos
user_metadata.imagespara buscar solo podremos hacer un sort en mongo usando ese campo. - No indexan campos vacios, es decir los ignoran y los guardan en el indice (son lo que se conoce como SPARSE)
- No podemos hacer búsquedas haciendo coincidir un array al completo, solo campos sueltos
- No podemos hacer búsquedas con un
not equal nullporque no tiene esos elementos y no comprende que hacemos.
HASHED INDEX
En estos índices lo que hace Mongo es convertir el valor del campo en un hash único y lo almacena. Este formato puede ser útil, en general para ahorrar espacio o para temas de sharding (comprime los documentos hijos en un hash), ya que en lugar de almacenar el campo almacena un hash. Luego Mongo por si mismo hace su magia y cada vez que busques va convirtiendo el directamente el valor de los campos, es decir, nosotros no tenemos que hacer nada.
db.getCollection('index').createIndex({ alias: 'hashed' })
Importante:
- No admiten búsquedas por rango solo exactas
- No admiten coumpound index
OTROS INDICES
- 2D: Indices basados en coordenadas de planos 2d
- 2Dsphere: Indices en formato Tierra, es decir, pone un plano en formato esfera para gestionar las coordenadas
- geoHaystack: Indices especializados en planos 2d de tamaño pequeño
PROPIEDADES DE LOS INDICES
- TTL: Propiedad de single field index donde indicamos un tiempo de vida al índice para que elimine los documentos de la colección, util para colecciones de logs y cosas así. El valor que indiquemos no se puede cambiar, para cambiarlo tenemos que borrar el indice y crearlo de nuevo
db.eventlog.createIndex( { "lastModifiedDate": 1 }, { expireAfterSeconds: 3600 } )
También es posible indicar una hora de expiración si el propio campo es de tiempo
db.log_events.createIndex( { "expireAt": 1 }, { expireAfterSeconds: 0 } )
Esto haría que este documento:
db.log_events.insert( {
"expireAt": new Date('July 22, 2013 14:00:00'),
"logEvent": 2,
"logMessage": "Success!"
} )
Desapareciera a esa hora.
- Unique: Campos o combinaciones de campos que no se pueden repetir
db.members.createIndex( { "user_id": 1 }, { unique: true } )
db.members.createIndex( { groupNumber: 1, lastname: 1, firstname: 1 }, { unique: true } )
Este índice si no existe un campo lo guardará como null y no se podrá repetir
- Partial Index: Podemos crear indices que solo esten referidos cuando se haga un tipo de filtro, es decir, que solo se indexará algo si el documento cumple con el filtro que se le indica, es decir, si creamos este índice:
db.restaurants.createIndex(
{ cuisine: 1, name: 1 },
{ partialFilterExpression: { rating: { $gt: 5 } } }
)
Solo indexará cuando rating sea mayor que 5 (pero solo mayor que 5, no vale luego buscar por un mayor de 8), esto hace que consuma menos recursos el indice.
- Case Insensitive: Podemos crear indices con case insensitive, indicando el
localey elstrengthque queremos que use para la parte insensitive
db.fruit.createIndex( { type: 1},
{ collation: { locale: 'en', strength: 2 } } )
Para ver la diferencia en la comparación Pulsa aquí
- SPARSE INDEX: Con la opción sparse le indicamos que no guarde en el índice los documentos que no contengan el campo que le indicamos.
db.addresses.createIndex( { "xmpp_id": 1 }, { sparse: true } )
Tenemos que tener cuidado porque este tipo de indice puede no devolver todos los resultados, si usamos un filtro que contenga xmpp_id nos ignorará los que no lo tengan y si buscamos también por otro campo no nos aparecerá
-
Index intersection: Intersección de índices, resumiendo esta funcionalidad, si mongo cree que funciona puede hacer uso de dos indices para hacer una búsqueda. Por poner un ejemplo, si tenemos dos single index uno con ciudad y otro con población, si buscamos por ambos puede mezclar los indices para mejorar la búsqueda, pero solo la búsqueda no lo usaria por ejemplo si buscamos por ciudad y luego queremos hacer un sort por población.
-
background: Propiedad recomendada para que la colección no se bloquee mientras se rehacen los indices (aún así ojo con los campos que se tenga prevista un nivel alto de escritura)
db.addresses.createIndex( { "xmpp_id": 1 }, { background: true } )
Trabajando con indices
Ver indices de una colección
db.getCollection('index').getIndexes()
Esto nos muestra algo similar a esto:
[
{
"v" : 2,
"key" : {
"_id" : 1
},
"name" : "_id_",
"ns" : "indexninja.index"
},
{
"v" : 2,
"key" : {
"_fts" : "text",
"_ftsx" : 1
},
"name" : "TextIndex",
"ns" : "indexninja.index",
"weights" : {
"alias" : 5,
"bio" : 1,
"firstName" : 10
},
"default_language" : "english",
"language_override" : "language",
"textIndexVersion" : 3
},
{
"v" : 2,
"key" : {
"lastName" : -1.0
},
"name" : "lastName_-1",
"ns" : "indexninja.index"
},
Con la type_version del indice, la key por la que se ha realizado, el name que tiene el indice y el ns, es decir, la colección a la que pertenece
Eliminar un índice
db.getCollection('index').dropIndex("lastName_-1")
db.getCollection('index').dropIndex( { lastName: -1 } )
Esto nos devolvería algo similar a esto:
/* 1 */
{
"nIndexesWas" : 5,
"ok" : 1.0
}
Donde nos índica el número de indices que coincidian con esa condición y el resultado
Eliminar todos(o varios indices)
Para eliminar todos los indices:
db.getCollection('index').dropIndexes()
Y a partir de la versión 4.2 de mongo podemos indicarle un array con los nombres de los indices que queremos eliminar
db.getCollection('index').dropIndexes(["TextIndex", "lastName_-1"])
Ver el uso actual de los indices
db.getCollection('index').aggregate( [ { $indexStats: { } } ] )
Con esto podemos ver si se usan mucho o poco los indices actuales. Esto nos devuelve algo similar a esto:
/* 1 */
{
"name" : "TextIndex",
"key" : {
"_fts" : "text",
"_ftsx" : 1
},
"host" : "83165c61f9de:27017",
"accesses" : {
"ops" : NumberLong(2),
"since" : ISODate("2020-01-12T11:18:17.642Z")
}
}
/* 2 */
{
"name" : "_id_",
"key" : {
"_id" : 1
},
"host" : "83165c61f9de:27017",
"accesses" : {
"ops" : NumberLong(0),
"since" : ISODate("2020-01-12T10:22:38.796Z")
}
}
También podemos ver que se ha usado en cada query que realizamos con el comando que estamos usando continuamente (además de mogollón de información relativa a la query)
db.getCollection('index').find({ city: 'Madrid', email:'NinjaMaster@email.com' }).explain("executionStats")
Y si por ejemplo queremos ver info extra cuando tenemos una busqueda con multiples condiciones, como un poco el orden de filtro que ha seguido con:
db.getCollection('index').find({ city: 'Madrid', email:'NinjaMaster@email.com' }).explain("allPlansExecution")
Esta query ademas de lo anterior nos devuelve:
"allPlansExecution" : [
{
"nReturned" : 5,
"executionTimeMillisEstimate" : 0,
"totalKeysExamined" : 5,
"totalDocsExamined" : 5,
"executionStages" : {
"stage" : "FETCH",
"nReturned" : 5,
"executionTimeMillisEstimate" : 0,
"works" : 6,
"advanced" : 5,
"needTime" : 0,
"needYield" : 0,
"saveState" : 0,
"restoreState" : 0,
"isEOF" : 1,
"docsExamined" : 5,
"alreadyHasObj" : 0,
"inputStage" : {
"stage" : "IXSCAN",
"nReturned" : 5,
"executionTimeMillisEstimate" : 0,
"works" : 6,
"advanced" : 5,
"needTime" : 0,
"needYield" : 0,
"saveState" : 0,
"restoreState" : 0,
"isEOF" : 1,
"keyPattern" : {
"city" : -1.0,
"email" : 1.0
},
"indexName" : "city_-1_email_1",
"isMultiKey" : false,
"multiKeyPaths" : {
"city" : [],
"email" : []
},
"isUnique" : false,
"isSparse" : false,
"isPartial" : false,
"indexVersion" : 2,
"direction" : "forward",
"indexBounds" : {
"city" : [
"[\"Madrid\", \"Madrid\"]"
],
"email" : [
"[\"NinjaMaster@email.com\", \"NinjaMaster@email.com\"]"
]
},
"keysExamined" : 5,
"seeks" : 1,
"dupsTested" : 0,
"dupsDropped" : 0
}
}
},
{
"nReturned" : 0,
"executionTimeMillisEstimate" : 0,
"totalKeysExamined" : 6,
"totalDocsExamined" : 6,
"executionStages" : {
"stage" : "FETCH",
"filter" : {
"email" : {
"$eq" : "NinjaMaster@email.com"
}
},
"nReturned" : 0,
"executionTimeMillisEstimate" : 0,
"works" : 6,
"advanced" : 0,
"needTime" : 6,
"needYield" : 0,
"saveState" : 0,
"restoreState" : 0,
"isEOF" : 0,
"docsExamined" : 6,
"alreadyHasObj" : 0,
"inputStage" : {
"stage" : "IXSCAN",
"nReturned" : 6,
"executionTimeMillisEstimate" : 0,
"works" : 6,
"advanced" : 6,
"needTime" : 0,
"needYield" : 0,
"saveState" : 0,
"restoreState" : 0,
"isEOF" : 0,
"keyPattern" : {
"city" : -1.0
},
"indexName" : "city_-1",
"isMultiKey" : false,
"multiKeyPaths" : {
"city" : []
},
"isUnique" : false,
"isSparse" : false,
"isPartial" : false,
"indexVersion" : 2,
"direction" : "forward",
"indexBounds" : {
"city" : [
"[\"Madrid\", \"Madrid\"]"
]
},
"keysExamined" : 6,
"seeks" : 1,
"dupsTested" : 0,
"dupsDropped" : 0
}
}
}
]
Recomendable que los índices entren en la RAM, asi nos evitamos tener que tirar de disco para consultarlos
Para ver lo que ocupan los indices solo tenemos que lanzar el comando
db.getCollection('index').totalIndexSize()
El resultado está en bytes
Ver toda la info posible de una colección
db.getCollection('index').stats()