

En este posts veremos 2 configuraciónes básicas para manejar el estado de salud de nuestros pods. Con estas configuraciones kubernetes de manera automática puede por ejemplo reiniciar un pod o no mandarle tráfico.
Para esto tenemos estas 2 propiedades:
- livenessProbe: Si esta sonda falla kubernetes puede por ejemplo reiniciar el pod. Es el típico health que solemos tener en otros servicios. Como tal se puede configurar que tiene que hacer kubernetes cuando la sonda falla, como por ejemplo cuantos errores debe dar antes de reiniciar y cosas así
- readinessProbe: Hasta que esta sonda no funcione kubernetes no enviaría tráfico al POD (no lo añadiría al objeto service que veremos más adelante lo que es) y en el caso de que empiece a devolver errores dejaría de enviarle tráfico (lo quitaría del objeto service)
Para ver como funciona esto, lo primero eliminaremos el pod actual si lo tenemos todavía activo
kubectl delete pods mario-test
Y modificaremos el fichero del POD añadiendo estas propiedades. Primero con la de liveness
apiVersion: v1
kind: Pod
metadata:
creationTimestamp: null
labels:
run: mario-test
name: mario-test
spec:
containers:
- image: pengbai/docker-supermario:latest
name: mario-test
ports:
- containerPort: 8080
name: game // <- Esto es nuevo
resources:
requests:
cpu: 50m
memory: 64M
limits:
cpu: 50m
memory: 64M
livenessProbe:
httpGet:
path: /fake
port: game
dnsPolicy: ClusterFirst
restartPolicy: Always
status: {}
Antes de hablar de la configuraciónd de la sonda comentar que hemos añadido un nombre al puerto en cuestión del contenedor para que nos sea más fácil hacer referencia a él y no tener que cambiarlo en un montón de sitios si de repente cambiamos el puerto.
Además del nombre del puerto hemos añadido la propiedad livenessProbe, dentro de esta propiedad podemos incluir comandos, peticiones a http y otras cosas que nos pueden resultar útiles para realizar la comprobación del estado de salud (al final del post pondré el link de la documentación para ampliar información). En nuestro caso hemos añadido una petición get a un path /fake que realmente no existe, para que veamos que ocurre.
Guardamos y creamos el pod como hasta ahora
kubectl create -f mario.yaml
Y veamos que pasa si ejecutamos nuestro comando get pods
kubectl get pods
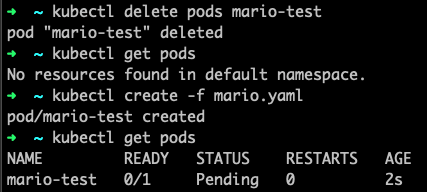
En un principio parecería que todo esta correcto pero si esperamos veremos como se producen cambios, normalmente a los 30 segundos empezaremos a ver diferencias

Vemos como se ha reiniciado una vez y si esperamos 5 loops tendremos este error y también ha cambiado el número de contenedores READY a 0

Por último si comprobamos el describe del pod en cuestión podremos ver el registro de los eventos que se han ido sucediendo
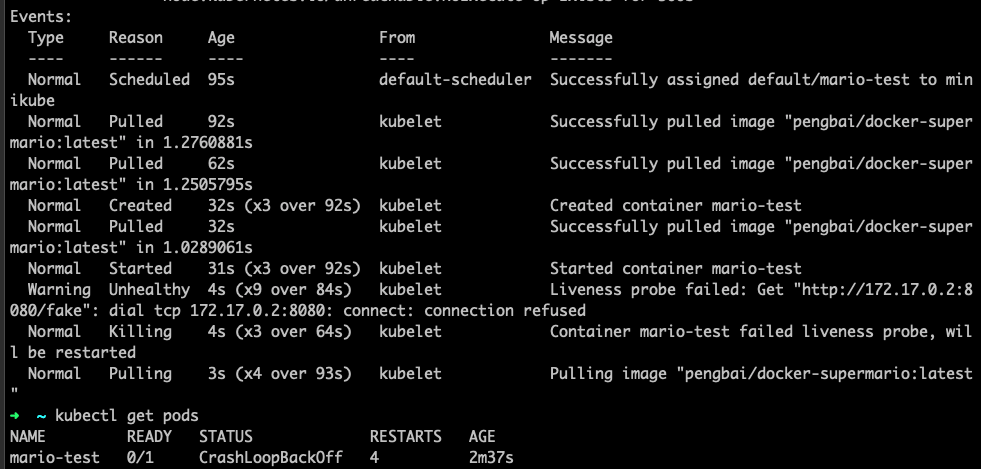
Este sería el caso usando livenessProbe, como tal hemos visto como ha intentando reiniciar cada 30 segundos hasta que ha confirmado que no funciona. Si analizamos el describe un poco más arriba veremos como en la configuración por defecto se comprueba cada 10 segundos con un máximo de 3 fallos hasta que reinicia (estas son serian algunas de los campos que podemos configurar)

Hagamos la prueba ahora usando readinessProbe
apiVersion: v1
kind: Pod
metadata:
creationTimestamp: null
labels:
run: mario-test
name: mario-test
spec:
containers:
- image: pengbai/docker-supermario:latest
name: mario-test
ports:
- containerPort: 8080
name: game
resources:
requests:
cpu: 50m
memory: 64M
limits:
cpu: 50m
memory: 64M
readinessProbe:
httpGet:
path: /fake
port: game
dnsPolicy: ClusterFirst
restartPolicy: Always
status: {}
Este caso si ejecutamos el get pods podemos ver como ya al inicio cambia un poco, nunca tenemos el pod en READY, si nos fijamos estamos siempre en 0/1

Y trás algunos reinicios, si esperamos 3 minutos tenemos un error

Por último veamos que tenemos en nuestro describe. Primero podemos ver la configuración por defecto (la misma que con liveness):
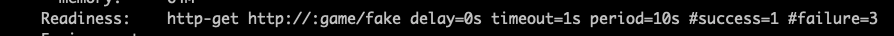
Y si nos vamos a los eventos que han ido sucediendo tenemos
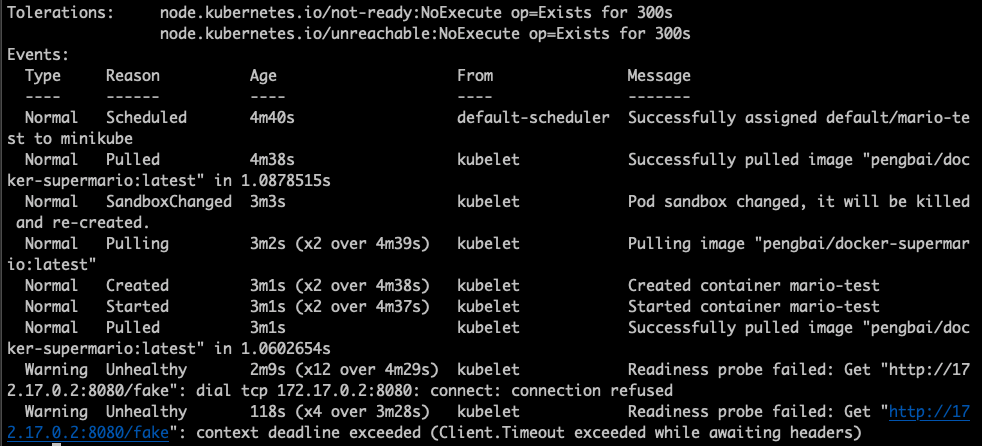
Vemos como ha intendado varias veces acceder a el y no ha sido capaz devolviendonos el error que ya hemos visto.
Estas han sido dos configuraciones básicas que podemos hacer, en la documentación oficial tenemos más información sobre la configuración, a que afecta realmente cada caso y otro probe más que es el de startup, recomiendo encarecidamente leerla y hacer más pruebas para ver las posibilidades que nos ofrecen los checks de estado de salud sobre nuestros pods.
Y hasta aquí este post, nos vemos en el siguiente un abrazoooorrrrr